How to Use GPT 3.5 Turbo For SERP Analysis to Identify Low-competition Keywords at Scale
ChatGPT and generative AI have drastically changed the landscape of SEO. From AI Content Creation, to optimising title tags to increase CTR, to even writing code to solve complex rendering and indexation problems—across the spectrum, the SEO Community has found some amazing use cases for Generative AI.
However, one largely under explored usage is the potential for GPT to be used for advanced types of SERP analysis that would typically require the trained eye of an SEO specialist, or the application of advanced pattern matching techniques.
In today’s blog post we’ll look at how you can use a combination of Arefs SERP Data, GPT For Work and the GPT-3.5 Turbo API to unearth extremely low-competition keywords, at scale and cost-effectively!
Using GPT 3.5 Turbo to Identify Irrelevant Results Ranking For Your Keywords at Scale
GPT 3.5 Turbo and ChatGPT (3.5 Model) are actually adept at determining the relevance of results ranking in relation to the keyword in question based on the title tag of the ranking result. If you have been in SEO for a meaningful amount of time you know the best keywords to target are the ones that have not been targeted at all.
For audiences that may be unfamiliar with the concept, it is probably worth taking the time to illustrate the concept using a real world example. Essentially, the strongest weighted ranking signal for Google is “relevance”:

Before Google assesses attributes like quality and backlinks, it looks at whether there are relevant results across the web. If there are no relevant results ranking for a query, then you can rank for that keyword fairly easily by creating relevant content. This is typically how low DR and low authority websites are able to rank for keywords. To illustrate this, let’s look at a specific example. In our example we’ll use the keyword “3rd gen 4runner wheels.”:

If we look at the results above we can see that a DR 10 and a DR 11 website are ranking in the top two organic positions below the image pack, ahead of a DR 16 website with page-level links and a DR 46 website. Why is this? It’s simply because the other results are just not relevant enough in relation to the query to rank, so lower authority websites that have relevant pages outrank the higher authority websites that have less relevant pages. The only time we really observe an exception to this rule is in the event that a website has been demoted or promoted by Google’s Reviews System, or if a higher DR website has been subjected to another type of penalty, that being manual or algorithmic. In our example below you can see that the title tags for the 3rd and 4th positions are “3rd gen 4Runner Exterior Accessories” and “3rd Gen 4Runner Aftermarket Wheel Thread Page 9” for the keyword "3rd gen 4runenr wheels." If I were a user searching for 3rd gen 4Runner wheels I would likely view both of these title tags as being irrelevant to my query, and so does Google, it just has no other content to serve!

- When using pattern matching it becomes difficult to account for synonyms and natural language within large datasets.
- Pattern matching doesn’t allow you to account for results that might be relevant to a users' query despite not using the keyword in the title tag.
- Pattern matching doesn’t “understand” context.

In addition, GPT-3.5 Turbo also does a good job at understanding context which pattern matching and even the most advanced form of custom regular expressions fail to accomplish.
In our example below we see that ChatGPT understands the second ranking result which has a title tag of “1996-2002 4Runner Aftermarket Wheels” as being a relevant title tag because 3rd Gen 4Runner wheels are wheels made for 4Runners produced between 1996-2002:

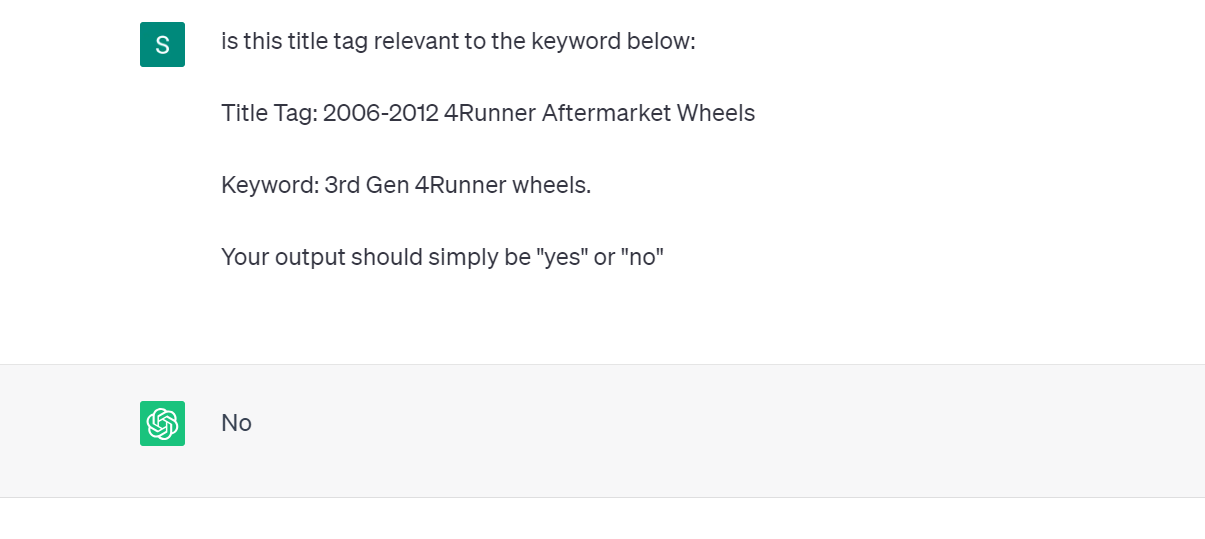
This type of rich contextual understanding gives GPT an unprecedented ability to identify irrelevant results ranking for any given keyword.
So, what is a user-friendly way that we can use GPT 3.5 to identify keywords with irrelevant results ranking at scale? Though there are various, and perhaps, technically more sound ways to do this, we'll walk through a practical and easy-to-understand example to demonstrate the concept in practice.
First, to get started you will need to register for an Ahrefs account (you will need to register for a standard account or above to be able to export SERP data), and in addition you will need to sign up to OpenAI’s API and generate an Open AI API Key. Finally, you will need to add the GPT For Work and Sheets Addon.
Step 1: Create a Google Sheet

Step 2: Export Your Ahrefs SERP Data For Your Seed Keyword(s)
After typing in your seed keyword(s) export the associated SERP Data from the matching terms report:

Ensure to include the top positions from the SERP in your export:

After exporting your data upload your export sheet directly into sheets. Once you have uploaded your data you are going to want to filter by organic listings only in order to keep the data clean (the data risks getting a bit muddied if you include other result types):
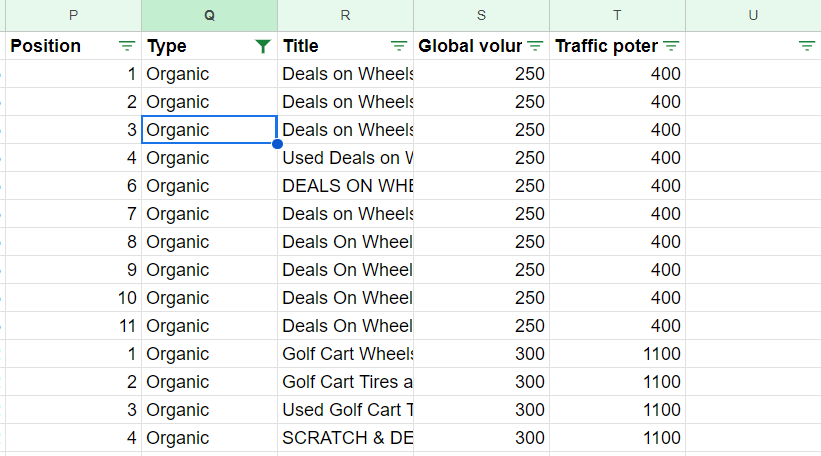
After filtering by organic, you can then export your data into the SERP Data sheet:

Step 3: Craft Your Prompt Your SERP Analysis

Step 4: Label Your SERP Data Using the GPT Prompt Function and Your Prompt
For this example we’ll simply add a column called “Relevant?” and in order to label the title tags we’ll use the GPT function made available by GPT For Work to label our keywords:
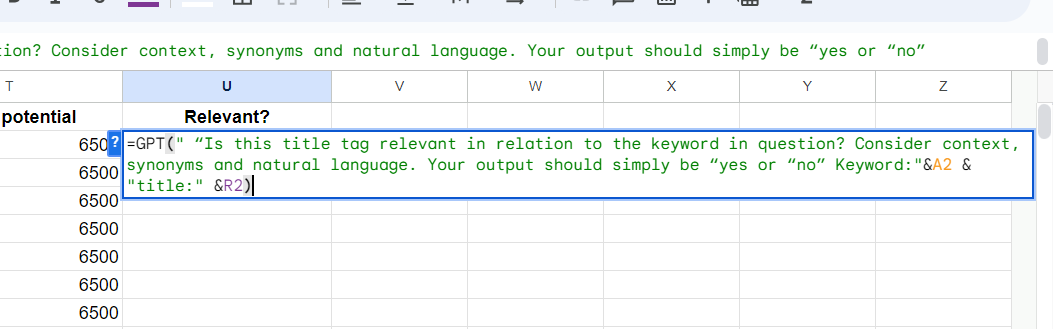

Step 5: Use a Countif Function to Count the Number of Irrelevant Title Tags For Each Keyword

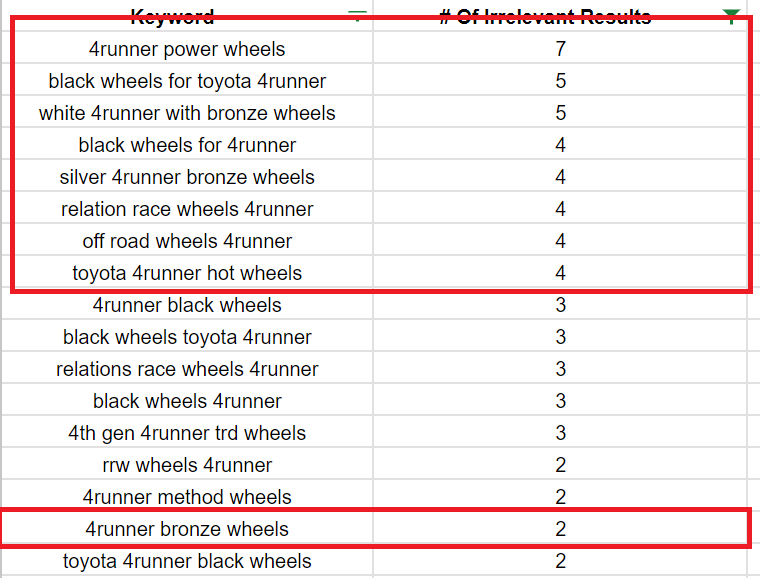
Step 6: Filter Keywords By Descending Order to See the Keywords With the Lowest Levels of Competition

The Results of The Process
Great Collection Pages For Low-competition Keywords



Awesome Brand Pages For Low-competition Keywords



Summary of Results
The type of filtering we employed above, also gives you an advantage over a lot of filtering techniques such as DR filtering that would not likely identify these types of low-competition keywords because of high DR websites outranking with irrelevant results.
Advice and Caveats
- If you decide to use GPT For Google Sheets and Docs you will only be able to label about 500 rows of data per minute, otherwise, you’ll receive an error saying you surpassed your rate limit, so don’t try to label more than 500 rows at a time.
- If you are working with a dataset of more than 10,000 rows of SERP data and don’t want to get “too codey” you’ll want to make use of a macro. Otherwise, the labelling process is time consuming and monotonous.
- With a single API account you can label about 30,000 to 40,000 rows of SERP data per hour, if you have a really large dataset take this into consideration.
- When selecting an API, pick the GPT 3.5 Turbo which is the most cost effective and fastest option.
- Avoid trying to include multiple title tags in a prompt, as it decreases both accuracy and counter-intuitively costs more tokens.
- Remember that it costs about $5.00 per 100,000 rows of SERP data you analyse (roughly equally to about 10,000 keywords).
- Frequently replace formulas with values as you might lose as all of your formulas, as they will reset if you leave and come back to the Google sheet.
- GPT-3.5 is fairly generous in rewarding relevance to a title tag, so, when it does not reward relevance it’s a really strong indication it’s a low-comp SERP, so take it seriously!
Working With Larger Datasets (10,000 + keywords)
- You’ll hit rate limits per minute fairly quickly while running this type of analysis, you’ll want to consider using an exponential backoff and you might also want to check out OpenAI’S Python notebook which discusses rate limits and how to deal with them while using Python. You can also request a rate limit increase using the OpenAI API Rate Limit Increase Request Form.
- For anything beyond 30,000 + keywords the associated SERP data for keywords becomes pretty large and you’ll hit the Google Sheets 10 million cell limit quickly, so I wouldn’t recommend using Google sheets for any dataset containing more than 30,000 keywords and 500,000 rows of associated SERP data.
- The example makes use of exported SERP Data, however, for larger datasets you’ll want to pull directly from the Ahrefs API, refer to the SERP Overview Documentation.





Comments
Post a Comment